Why AI? What we get wrong when discussing modern Deep Learning.
The attention of the general public and big industry has been firmly captured by the emergence of modern AI and Deep Learning since about 2020, at which time I was about 1 year into my PhD in the field. I was super excited to see the growing interest in the field that I'd been studying and trying to contribute to.
As the interest in this area grew I often found myself in conversation with those in industry about their plans to use these new modern methods to solve whatever problem they were currently facing. I’d often comment that it sounds like they’ll have a lot of work ahead of them to collect enough of the right data to make it work. To which they’d respond with a wave of the hand that they’ve already got a bunch of data from such-and-such study done a few years ago, and now they just need to work out what “AI model” to use. At this point I’d usually wish them luck and let them go on their way…
A common conversation…
The motivation behind this blog is to address what I see as some fundamental gaps in how “AI” is often presented and discussed, especially in industry. There's a lot of hype, a lot of terminology, and a lot of bold claims about how “AI” can solve this problem, and that problem, and the next problem. Companies are releasing AI products left and right. But in both the general public and even within technical circles, I think discussions often miss the central point of “AI”. Not just why it’s so revolutionary, but how it’s able to automate things that used to be thought of as impossible to automate. I think this lack of understanding leads many business, product and policy decisions to miss the mark, sometimes by quite a large margin.
So in essence I want to talk about:
Why AI?
Not just what it is, but why we even bother using these techniques and what motivated the shift toward what we call “AI” today.
Now, to be precise, when people talk about “AI” in the modern age, they’re usually referring to techniques within a subset of machine learning, “Deep Learning”. These are the techniques behind large language models, generative image and video models, object detection and so on.
So what I want to explore is:
Why do we use these new techniques?
Why not use others?
What were the alternatives, and where do they fall short?
What makes deep learning different or useful?
What new issues do these Deep Learning Methods bring?
And we’re going to start by abandoning the term “AI” .
Frankly, the term “AI” is simply a marketing term. It doesn’t have a technical definition and means whatever the speaker wants it to mean. Instead, we’ll talk about algorithms and automation. Specifically I'm going to be comparing what I’ll refer to as traditional algorithms with machine learning (ML) algorithms, which I also like to refer to as data-driven algorithms.

This is now an “AI” free zone.
Traditional Algorithms
Let’s go right back and talk about what an algorithm is.
We’ve heard this term a lot, everyone talks about algorithms and how they now power everything. At its core, an algorithm is just a method, or a step-by-step process, for automating a task using code, running on a computer.
The logic, or decision making process is encoded in software, and might also involve some maths in the form of equations. So algorithms do now power everything, but that’s mostly a consequence of us moving to a more digital world where various processes are now mostly done on a computer.

Can YOU see where this algorithm goes wrong?
What makes what I'm calling “traditional algorithms” different from ML is that their creation relies heavily on human input. A person has to work out the logic, do the math, and then code it up. The upside to this is that you can explain exactly how the algorithm works, why it works, any issues that there might be and how to improve or adapt it in the future.
But traditional algorithms fall short when the task we’re trying to automate is too complex to clearly define. This is especially true when working with complicated high-dimensional or messy datasets. In some cases, it’s nearly impossible to write down a clean, logical sequence of steps.
A good example of this is the case of image classification which is the task of sorting images into a fixed set of categories. How do you program a computer to tell the difference between a cat and a dog in a photo? We humans find this task incredibly easy to perform, but we find it incredibly difficult to describe how we performed it in a way that can be replicated.
To a computer, an image is just a big grid of numbers (pixels). Coming up with a series of logical steps or math formulas to reliably extract the “cat” or “dog” from that grid is incredibly hard. And it is tasks like this where traditional methods hit a wall.
The Machine Learning Approach
This is where machine learning comes in. Specifically for this article we’re going to talk about deep learning, but a lot of what I talk about will also be true for other methods as well.
The basic outcome from deep learning based algorithms is the creation of a method that can take some input data source and extract or predict some information from it. And you can really define all deep learning tasks in this way.
The fundamental motivation behind why we should be able to do this with Deep Learning, is the idea that if the input contains the information we care about, then there must exist some mathematical function or equation that can extract it.
More generally, we can say that if there is some connection between two pieces of information, then there should exist an equation that links the two. We might not know what that equation looks like, but we assume that this “True Equation” exists.

The equation is right behind here, trust me.
As an example, imagine a farmer wants to know how to improve their yield for a certain crop. They experiment with different amounts and types of fertilizers, different quantities of water and different light levels. The farmer knows that all of these things impact the growth of the crop but the specific biological processes and interactions involved in determining what the specific yield from the plant will be are extremely complicated. However this process is not random, there is a consistent logic behind it and we can therefore represent it with an equation or "mathematical function”.
Deep learning uses deep neural networks, which are general-purpose function approximators. This means that these general purpose mathematical models can, in theory, represent any function if we tune (or train) them properly.
With equations like these, we don’t need ML…
So instead of trying to manually figure out the equation, we collect a large set of input-output pairs which we call a training dataset. Then, using additional training algorithms, we adjust the internal parameters of the neural network to “fit” the data—hopefully arriving at an equation that generalizes well and performs the task we want.
Have I lost you?
Now I’ve said a lot of technical terms there, so let's break it down to something simpler. A very simple machine learning task is basic line fitting. Many different fields and industries will use this technique, and you may have even been taught some method to perform it yourself. Now that method may not have been referred to as “Machine Learning”, but fundamentally that’s what it is (assuming it was performed by a computer and not by hand).
Line fitting requires us to find the two values or “parameters” of the line equation such that the resulting line best fits the given data.
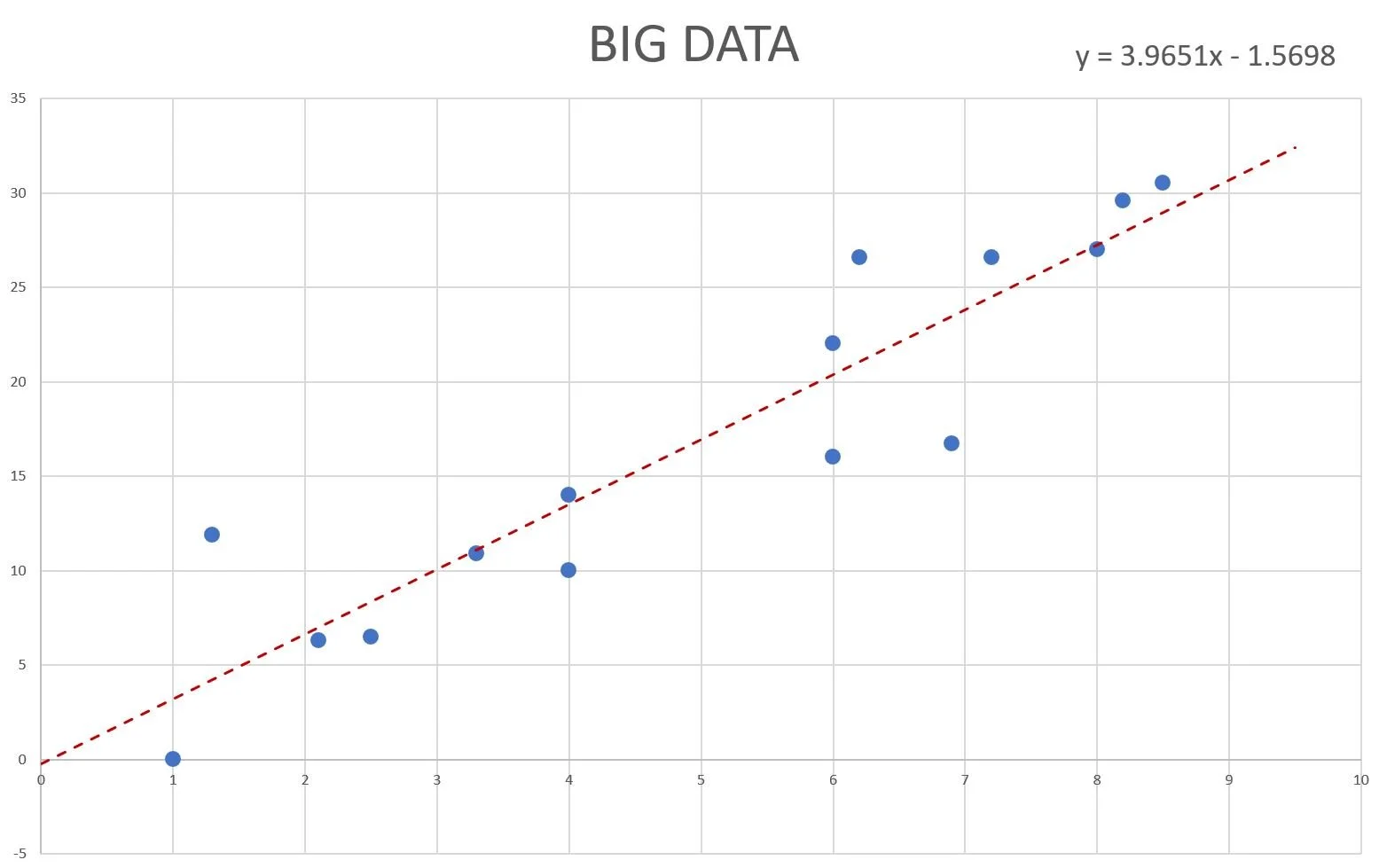
A simple line of best fit with parameters 3.9651 and - 1.5698
In deep learning, our deep neural networks are just more complicated equations, and they can take many many different forms, depending on the specific task. But don’t worry, what those different forms are is not something we’re going to worry about here!
It’s important to just know that the “training” process of deep learning simply refers to finding the parameters of the neural network equation using training algorithms. You may have heard of the term “gradient decent” in relation to training neural networks. Gradient descent is a class of algorithms used to find the best parameters of our neural network equation. And that’s all you need to know about that for now!
Ultimately, Deep Learning is the approach of using autonomous algorithms to automatically produce other autonomous algorithms, using data.
And then what?
At the end of training, the hope is that the parameters that we get gives us the equation that not only best fits the training data, but that the solution encoded in that equation is, or close to, the “True” equation, that we talked about before.
In almost all practical cases it is impossible to know if we have actually created this true equation. As in many cases knowing if we had, would require us to have the “True Equation” in the first place.
So how do we see how close we may have gotten? We test it using data that was withheld and not used during training! If our equation has the same, or close to the same, performance on the test data as the training data, then we can say that equation, or the solution we found generalises. This gives us confidence that when we use it out in the real world, it will perform as expected!
Isn’t that obvious?
One of the most amazing things about deep learning is this observation that once we train our neural network on our training data, the solution it comes up with (if done correctly) also works on data not in the dataset! There isn’t really anything in the training process that dictates that the solution it comes up with SHOULD generalise to any other data of the same type that we trained with. It just does, and we don’t really have any really solid ideas as to why this happens, there are some good ideas, it’s just really complicated to prove.
To drive home what I'm saying here, imagine you have a dataset of images of cats and dogs that are labeled. Here our data is not just the images, but also the labels themselves. If we were to train a Deep Neural Network (say a Resnet50 for those who are interested). If we were to train this to correctly predict whether the image contains a cat or a dog, we would hope that we would get a pretty good accuracy, it’s a pretty easy task for modern deep learning.
We would further hope that if we were to give the trained model any picture of a cat or a dog it would also correctly extract that information from the image.
Realistic depiction of Deep Learning.
Yes, and?
Now what do you think would happen if we randomly shuffled the labels on our images, so whether we labeled an image cat or dog would be completely random, and we then trained the same Deep Neural Network on this new data? Well you might expect the neural network to not be able to learn anything! As I did say before, the data sources, in this case the image and the label, have to be related in some way to create this “True equation”.
But no, the Neural Network can learn to exactly memorise this random dataset and achieve a high accuracy. However if we were to test it on our withheld dataset, the performance will be no better than flipping a coin. The model hasn’t “learnt” anything, it has just “memorised”.
If we want to create an equation, with our neural network, to model some process that does generalises to any data of the same type, then there must be a connection between our input and output. The amazing part of Deep learning is that when this connection exists, Deep Neural Networks tend to come up with a solution that does generalise.
But why?
When these Neural Networks can just memorise the training set and not care about any other data, why do they instead come up with a more general solution? Well as I said, it’s complicated and we’re not 100% sure. But the simplest and most straightforward explanation I can give is that Deep learning as a whole (that is the neural networks and the training algorithms) is lazy.
It will always look for the simplest solution.
This is great because memorisation is hard! So instead if you can find some connection or some pattern in the data that you can use to get the answer you can use that as a shortcut instead of having to memorise the answer! And this is what it means to have a general solution to a problem!
We all know the KISS principal, Keep It Simple Stupid.
Which is a good idea because a simple solution is the one that is most likely to apply to the most situations and have the fewest issues!
It’s good to be lazy?
There is however a downside to this “lazy” behavior of Deep Neural Networks. The solution that the Neural Network comes up with is the simplest solution for the training data. So what happens if we don’t collect enough of the right types of data so that the simplest solution to the training and test data does not apply to the “real world”?
To motivate this, let's see a popular example.
Here we have a dataset of images of Huskies and Wolves that are all correctly labeled. We train our Deep Neural network on this data and get good performance.

Look at all that data…
Now let’s test out in the real world!
We’ll use the model to process images from some trail cameras we’ve set out in the wild. But now we find that the performance is terrible! Its predictions are all over the place, it says Wolves are Huskies and Huskies are Wolves!
But if we look closely at its prediction on certain images, and the dataset itself, we start to piece together the problem. Looking at all the images of the Huskies in our dataset we can see that the background is always grass and the Wolves are always in the snow. And if we look at the predictions from our model on the trail camera images, whenever the animal is on grass it is predicted as a Husky and if it is on snow it is predicted as a Wolf!
Hopefully you can see what has happened here! The simplest solution that our Deep Learning algorithm found was to just look at the background! Is there a lot of grass? Husky. A lot of snow? Wolf!
It would be a lot harder to actually look at the animals and try and discern the subtle difference in the features that distinguish a Wolf and a Huskie, so it didn’t bother!

Looks like a Wolf to me!
Now what is the solution to this? We need to make sure that the only constant in our images of both the Husky and the Wolf IS the Husky and the Wolf. Of course there are practical exceptions we can make. If we KNOW we will only see these animals outside in forest-like environments, then we don’t need to include images of them inside or in strange environments like the desert.
This is just one example of what I like to call…
“Asking the wrong question with your model inputs”
And asking questions is exactly how I want you to think about interacting with Neural Networks:
Asking questions and getting answers.
But what question you ask is dependent on what data you have trained the model on, not what you’re thinking in your head!
Yes I can read your thoughts!
This idea is what we’re going to spend the rest of our time together on. Thinking about Deep Learning this way will help you better understand what problems we can solve with Deep learning and what data you’ll need!
To provide another example of what this might look like in the real world. Imagine you wanted to create a model that can determine whether a certain crop is showing signs of a specific disease or not. So you collect images of that crop that you know do have the disease (or would go on to develop it). You also collect example images of healthy crops. Unknown to you all of the example images you collected of the problem crops were taken at the same time of day, say 11am. The example images of healthy crops on the other hand were taken at different times of day!

Rows and rows of data…
Hopefully it’s not unsurprising to you now that the simplest solution our trained model may find is to just identify the lighting or position of the sun in the image. The model will then “say” the crop is showing signs of disease whenever it looks like the image was taken at 11am!
Now substitute the time the images were taken with other constants. Maybe the images of the diseased crops were all taken from a specific field, specific farm, or in a specific country. Don’t be surprised if the trained model just ends up identifying a specific field, farm or country and NOT signs of disease in the crops!
This sort of issue shows up all the time in applications of Deep Learning and has likely killed many projects! It is for THIS reason that we must collect a lot of data. We must collect enough data so that the only constant is the thing we want to detect!
Yeah, but I have plenty of data!
But let's assume we’ve collected enough of the right data to train our model correctly, what else could go wrong? Let’s go back to the example of our images of cats and dogs and have a look at exactly what our simple trained Deep Neural Network gives us.
So in this example we are performing the task of classification. This is where we sort the input into one of a fixed number of categories, in our case there are two. We know our Neural Network is an equation, just like our line equation, so a natural question you may have is “how does an equation tell us if this image has a cat or a dog in it”.
Well without going into too much detail, the answer is…
It doesn’t.
What it does give us is a value for both categories, cat and dog. These values specify how likely the model believes that the input contains the object in the corresponding category rather than the other.

Kitty goes in, numbers come out
If we wanted to be more technical, Neural Networks produce the parameters of a probability distribution. What type of probability distribution it is, whether it is continuous or discrete, and what we do with it depends from task to task. But let's not worry about that…
For our cat/dog classifier, you can imagine these two values represent the probability of heads/tails for a biased coin flip. What do we do with these values? Well, we can flip the coin and randomly sample an outcome. The category with the highest probability will be more likely to be chosen. More commonly, we just simply take the maximum probability as our answer as this is the outcome the model has given the highest likelihood to.
Seems a bit convoluted…
But why do we do it like this? It all goes back to asking questions and the idea that there needs to be a connection between the input and the output.
In our image of a cat there is a whole bunch of information that has nothing to do with the cat. During training we tell our model that there is a 100% chance that this image contains a cat and 0% chance that it contains a dog. The training algorithm tunes the parameters of the neural network to try to get the output probability distribution to match this.

But what is “cat“?
The issue is that there are many aspects/features of one species of dog that could be used to distinguish it from a particular species of cat that wouldn’t work for another species! So the Neural Network must use many different features and patterns and learn which are important and the relationships between them.
So at the end of training when we provide our Neural network with a new image, what we are really asking is, “how likely is it that the collection of features in this image, that you’ve identified as important, would show up in this category vs the other”.
To put it another way, say I asked you: “Go out and get me either a cat or a dog. But whatever you get me had to have short pointy ears, a long flexible tail, oval eyes and sharp claws.”
How likely would you be able to find a dog that had all those features? Not very likely, how about a cat? Much more likely.
We’re asking the Neural Network a very similar question! We’re asking: given what you have seen about cats and dogs from the dataset, how likely do you think that a cat has these features, and how about a dog? As we can see from this example, the model is not TELLING us if it is a cat or a dog, it is just telling us how likely the features of the animal in the image belongs to a cat VS a dog.

Some similarities, some differences, but what is important??
Wait, but what if…
This raises an interesting question, what happens if we provide the model with an image that is of neither a cat or a dog - how about a bird? Well, the model would look at the catdog-like features of the bird, the shape of its eyes, its claws and tail. It would then provide a value for both cat and dog on how likely it thinks that you’d be able to find each animal with these same features! Note that it will never say that it is a bird!
If the image is of something really unusual we’d ideally get a very low value for both cat and dog. But remember, the question we're asking is what is more likely? Cat or dog? In this case the best it can do is give us a 50/50 probability, meaning that it is equally likely (or unlikely) for both.
While this might be what we hope from our model for a random object, we must also remember that we’ve trained our model on images that always contained either a cat or dog! So in practice what we sometimes observe is that the model confidently predicts a very high value for one category or the other!
So it just gets it wrong? Duh!
So if we were to put an image of a toaster into the cat/dog model it may produce a very high likelihood for a cat, which would be incorrect…right? Remember what the model is actually telling us here. The combination of specific cat/dog like features in this image are more likely to represent a cat, rather than a dog. The important thing to note here is that the model is not necessarily wrong! It’s just that the question we asked the model is just silly!

A toaster, here drawn with the features of a cat.
We can only really trust the outputs of our Deep Neural Networks when we can be confident that we have not only trained them on enough of the right data, but that the data we input into them after training is appropriate for the question we are asking. The lack of awareness of this specific point I believe is a real issue. This slight nuance about Deep Neural Networks leads to a lot of incorrect thinking about the abilities of these modern algorithms and what they do.
We gotta fix the hallucination problem!!!
This phenomenon is very similar to what we would call “hallucination”. That term is typically used when referring to generative models like Large Language Models (LLMs) like ChatGPT, Claude and Gemini, as well as image and video generators. However, what is happening, or “going wrong” is exactly the same.
LLMs, for example, are trained with a large amount of textual data to simply predict the next word or token in the input sequence. When we want an LLM to generate long sequences of text, we add its output word/token back onto the input sequence and get it to predict again. If it gives responses that sound human, that's because it was trained on responses from humans. If it responds to a question with an answer, that’s because it was trained on a large number of question/answer examples.
But we have to be careful!
When we use an LLM the actual question we ask at every step is “Given what you have seen in the training dataset, what is the likelihood, for every single token in your dictionary, that it comes next in the input sequence, rather than any of the others”.
From that we can either pick the highest value, or randomly sample, with the tokens with the larger likelihoods more likely to be picked! We do this over and over until we get the whole response.
If the input sequence represents a text based question we are asking, and the response the LLM produces is a factually correct response, that is simply because, that sequence of words/tokens, is what would most likely come next according to the model given that data it was trained on.

But both responses are valid, the second model was just not trained on the information required to answer the question…
If the dataset does not contain any information about the question being asked, the model will still produce a response! Its response will be coherent but factually incorrect!
Again it’s important to note that, assuming the model is powerful enough and has been trained correctly, this factually incorrect response IS the correct answer to the ACTUAL question we are asking the model. Which is “Given what you have seen in the training dataset, what is the most likely next sequence”.
It gave us exactly what we asked for!
Well, yes it is still a problem…
The issue with this of course is that, apart from one response being factually incorrect, there is no difference between both of the responses! So in order to be confident that the answer to your question is correct, you must be confident that the information to answer your question appears frequently enough in the dataset for it to be the most likely response!
Just like providing the image of a toaster to the cat/dog model, we need to make sure that we are asking our trained model the right question with our inputs.
For LLMs this is fine with simple questions as modern LLMs are trained on huge datasets. But for more complicated and nuanced questions, we can never be 100% confident that the response is actually factually correct. We don’t know how often the information required to answer our question appears in the dataset, if at all!
Of course researchers are developing new methods and work arounds for this, my main goal is to change how you think about these so-called “hallucinations”. They are not “flaws“ in our models, they are issues with how we are using them. And if we are constantly trying to use our Neural Networks in ways that frequently lead to these “hallucinations”, perhaps we need to think about what exactly we’re trying to do…
So… Data?
So yes data is everything, why? Because data, and how we use it, defines the questions we are asking. And because of that we must be very careful of what data we use to train our models AND what we input into our models once they are trained. That way we can avoid asking nonsensical questions of our models like whether you’re more likely to find a cat that looks like a toaster or a dog. And we’re less likely to unknowingly receive answers to questions we didn’t want to ask, like whether an image is snowy or grassy when we want to know if there was a husky or a wolf.
Furthermore we must understand the role that Deep Learning fills. It allows us to turn data into automation solutions that work amazingly well. So long as they are used to answer questions the data can answer.